1.1 项目介绍#
学习目标#
- 知道什么是聊天机器人
- 知道黑马智聊机器人的项目架构
- 知道什么是大模型
- 知道大模型的分类
一、聊天机器人项目简介#
1 什么是聊天机器人#
- 概念:聊天机器人是一种基于人工智能的自然语言处理技术开发的软件程序,能够通过文本或语音与用户进行交互,模拟人类对话。它可以根据用户输入的问题或指令,生成相应的回答或执行特定的操作。
[图片缺失: F:/北京AI/bj_AI_python/python课堂视频资料/day01_黑马智聊机器人项目介绍_操作系统作用和linux系统命令详解/笔记/assets/20250219235132.png]
- 特点:
- 自然语言理解(NLP) :能够理解用户输入自然语言,包括文字或语音,并从中提取意图和关键信息。
- 对话管理 :通过对话引擎维持对话的连贯性,根据上下文生成合适的回答。
- 个性化交互 :可以根据用户的历史记录和偏好提供定制化的回答。
- 多功能性 :除了聊天,还可以执行任务,如查询信息、预订服务、提供帮助等。
2 项目需求分析#
项目旨在构建一个基于大模型的智能聊天机器人,利用其强大的自然语言处理和生成能力,为用户提供高效、精准、个性化的对话服务。 该聊天机器人将集成先进的大规模预训练语言模型(如GPT、Qwen等),具备自然语言理解、多轮对话、情感分析、知识问答等核心功能,并可根据具体应用场景进行定制化扩展,如客服咨询、教育辅导、娱乐互动等。 相关功能需求如下: (一)核心对话功能需求
- 自然语言处理 :
- 聊天机器人能够理解和生成自然语言文本,支持中文和英文对话。
- 能够处理用户的输入并生成准确、流畅的回复。
- 实时对话交互 :
- 用户可以通过 Streamlit 界面输入文本,聊天机器人实时响应并展示回复。
- 对话过程流畅,延迟时间不超过 3 秒。
(二)用户界面功能需求
- 简洁明了的布局 :
- 提供输入框、发送按钮和对话展示区域。
- 界面设计简洁美观,易于操作。
- 交互式体验 :
- 用户输入问题后,点击发送按钮即可触发对话。
- 聊天机器人的回复实时展示在对话区域。
根据上述功能需求,项目采用模块化设计,前端通过Streamlit等框架实现简洁易用的交互界面,后端基于Ollama等平台进行模型部署和管理,确保系统的高效性和可扩展性。 项目目标旨在开发一款基于自然语言处理技术的聊天机器人,能够通过网页界面与用户进行实时对话,为用户提供高效、便捷的交互体验。
了解了相关需求之后,如何搭建聊天机器人呢?我们一起看看整体项目架构
3 项目架构设计#
整体项目架构如下:
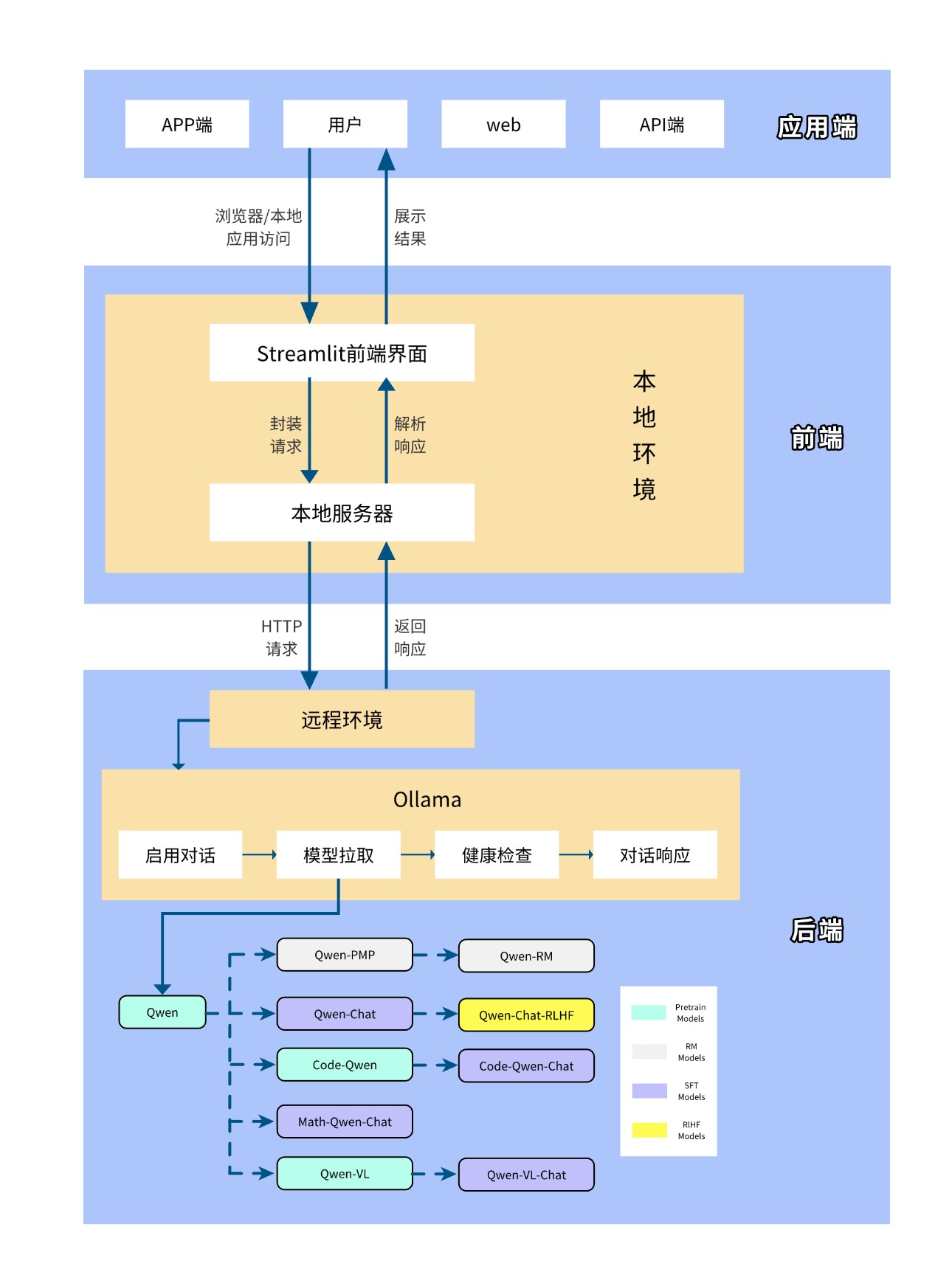 项目架构说明:
项目架构说明:
- 后端模型 :利用 Ollama 平台的 Qwen 模型,该模型具备出色的自然语言处理能力,能够理解和生成自然语言文本,为聊天机器人提供核心的对话处理功能。
- 前端界面 :采用 Streamlit 框架搭建用户界面,Streamlit 是一个简单易用的 Python 库,能够快速创建美观、交互式的 Web 应用,使用户能够通过网页与聊天机器人进行实时对话。
- 对话交互 :用户可以通过 Streamlit 界面输入文本,聊天机器人基于 Qwen 模型对输入内容进行理解和处理,生成相应的回复并展示在界面上,实现流畅的对话交互。
- 模型调用 :后端服务负责将用户输入传递给 Qwen 模型,并获取模型生成的回复,然后将回复内容返回给前端界面进行展示,确保对话的实时性和准确性。
- 界面展示 :Streamlit 界面提供简洁明了的布局,包括输入框、发送按钮和对话展示区域,用户可以方便地输入问题并查看机器人的回答,提升用户体验。
4 项目效果#
- 本次课最终目标是我们会带领大家利用python编程完成从0-1的聊天机器人搭建。

二、大模型核心基础#
1 什么是大模型#
大模型,通常指的是“大语言模型”,它是一个通过在海量文本数据上训练、能够理解并生成人类语言的超大型人工智能程序。 您可以把它想象成一个博览群书、学识渊博的超级大脑,它学习了互联网上几乎所有的公开知识,从而获得了强大的语言能力和世界知识。
2 大模型分类#
2.1 自然语言处理大模型#
自然语言大模型(Large Language Models, LLMs)是基于深度学习的模型,旨在理解和生成人类语言。它们通过大规模文本数据的训练,能够执行多种自然语言处理(NLP)任务,如专注于文本生成、理解、翻译等任务,GPT系列(OpenAI)、BERT(Google)、T5(Google)
2.2 语音大模型#
语音大模型是基于深度学习技术构建的人工智能模型,主要用于处理语音相关的任务,如语音识别(ASR)、语音合成(TTS)、语音翻译等。近年来,随着深度学习和大规模数据训练的发展,语音大模型在性能和功能上取得了显著进展,能够支持多语言、多场景的复杂任务。 举例:Whisper(OpenAI)、WaveNet(DeepMind)、讯飞星火
Whisper 由 OpenAI 开发的开源多语言语音识别模型,支持多种语言的语音转录和翻译 讯飞星火由科大讯飞推出的语音大模型,尤其在中文语音识别方面表现突出,支持多种方言和少数民族语言。此外,讯飞星火还具备强大的语音合成能力。 语音模型是一种将声音信号转换为数字信号的模型。
语音模型的应用场景
- 语音识别 :将人类语音转换为文本或其他可理解的形式,广泛应用于智能助手、语音输入和自动化客服系统。
- 语音合成 :生成自然、具备韵律且富有情感的语音,适用于多语言、情感丰富的TTS应用。
- 语音增强 :提高语音信号的清晰度和质量,常用于噪声环境下的语音处理。
- 声音事件监测 :识别环境中的特定声音事件,如警报声、机器故障声等。
- 说话人识别 :识别说话人的身份,常用于安全验证和个性化服务。
2.3 计算机视觉大模型#
视觉大模型(Large Visual Models)核心是通过大规模数据和复杂模型架构,实现对图像和视频的深度理解和生成。与传统计算机视觉模型相比,视觉大模型具有更强的泛化能力和多任务适应性,能够处理复杂的视觉任务,如图像分类、目标检测、语义分割、图像生成等。
Stable Diffusion、Vision Transformers (ViT)、DALL·E(OpenAI)、CLIP(OpenAI)

2.4 多模态大模型#
多模态模型是一种能够同时处理多种数据模态(如文本、图像、音频、视频等)的人工智能模型。与传统的单模态模型(如仅处理文本或图像)相比,多模态模型通过整合不同模态的数据,能够提供更全面、更准确的理解和生成能力。这些模型在多个领域展现出强大的应用潜力,例如医疗诊断、自动驾驶、智能助手等。
多模态模型的核心在于跨模态融合,即将不同模态的数据表示映射到同一空间,以便模型能够理解和生成跨模态的内容。例如,在视觉问答(VQA)任务中,模型需要同时理解图像内容和自然语言问题,以生成准确的答案。
举例:GPT-4(支持多模态)、Flamingo(DeepMind)、BLIP、KOSMOS(微软)
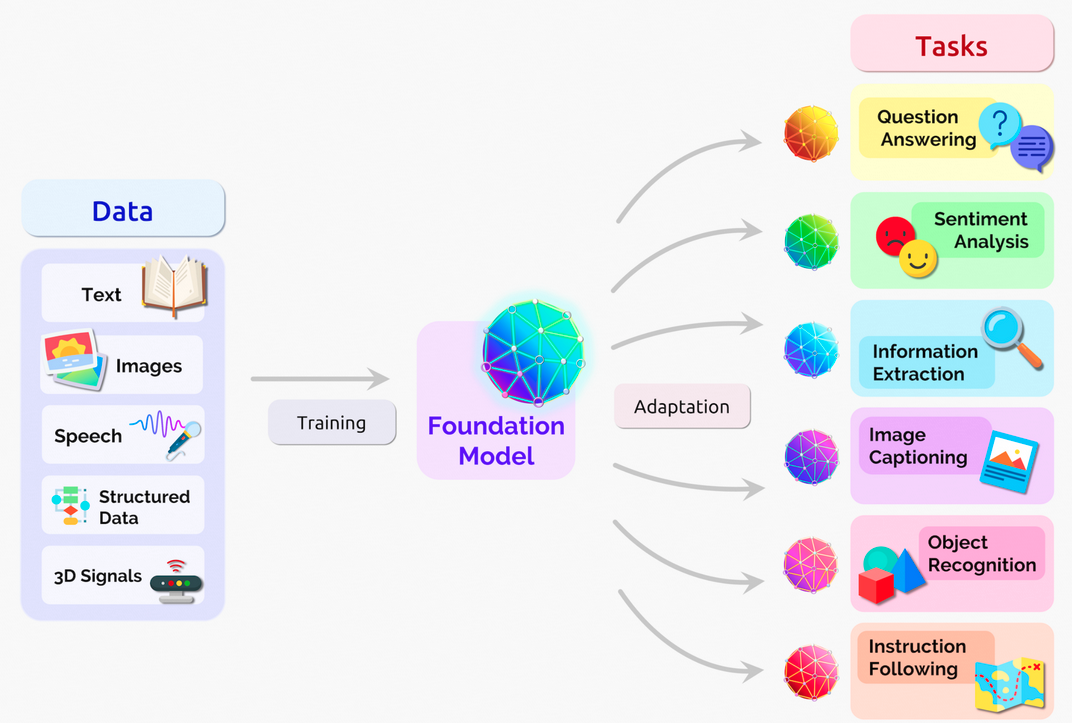 对上图解释如下:
对上图解释如下:
这里展示了一个基础模型(Foundation Model)如何通过训练和适应(Adaptation)处理不同类型的数据,并执行多种任务。以下是图中各部分的详细解释:
数据(Data)
基础模型的训练需要多种类型的数据,这些数据包括:
文本(Text):包括书籍、文章、网页等文本信息。
图像(Images):包括照片、插图、图表等视觉信息。
语音(Speech):包括语音记录、音频文件等声音信息。
结构化数据(Structured Data):包括数据库中的表格数据、电子表格等。
3D信号(3D Signals):可能包括3D模型、点云数据等三维信息。
训练(Training)
使用上述数据对基础模型进行训练,使其能够理解和处理不同类型的信息。
基础模型(Foundation Model)
训练完成后,基础模型能够执行多种任务,并通过适应过程进一步优化其性能。
适应(Adaptation)
基础模型可以通过适应过程针对特定任务进行优化,以提高其在特定应用场景下的表现。
任务(Tasks)
基础模型可以执行以下任务:
问答(Question Answering):回答用户的问题。
情感分析(Sentiment Analysis):分析文本中的情感倾向,如正面、负面或中性。
信息提取(Information Extraction):从文本中提取关键信息,如实体、关系等。
图像描述生成(Image Captioning):为图像生成描述性文本。
物体识别(Object Recognition):识别图像中的物体。
指令遵循(Instruction Following):根据用户的指令执行特定的任务。
这里展示了基础模型的强大能力,它可以通过训练和适应处理多种类型的数据,并执行广泛的任务,从而在各种应用场景中发挥作用。
3 大模型应用场景#
- 智能客服与对话系统:用于构建聊天机器人、虚拟助手,提供24*7的客户支持。目前大模型最广泛应用。
- 文本生成:生成文章、故事、代码、营销文案等。
- 机器翻译:实现多语言之间的高质量翻译。
- 问答系统:提供精准的问答服务,如知识库查询、技术支持。
- 图像分类与识别:识别图像中的物体、场景或人脸。
- 目标检测与跟踪:用于自动驾驶、安防监控等场景。

4 国内主流大模型#
深度求索 - DeepSeek
- 核心特点:“性价比之王”,实力黑马。 以其卓越的数学、代码和推理能力迅速崛起,并通过免费策略获得了大量用户。
阿里巴巴 - 通义千问(Qwen)
- 核心特点:“双轮驱动”,开源标杆。 既提供闭源的API服务,也大力投入开源,其通义千问开源系列(如Qwen2、Qwen2.5)在全球开源社区享有极高声誉。
智谱AI - ChatGLM
- 核心特点:学术背景,双语专家。 开源模型ChatGLM-6B 及其迭代版本在轻量化和双语对话上表现优异,拥有庞大的开发者社区。
字节跳动 - 豆包
- 核心特点:流量入口,场景丰富。 背靠字节跳动的庞大流量和内容生态(抖音、今日头条等),天生拥有丰富的应用场景和海量的用户数据。
讯飞星火(iFlytek Spark)
- 核心特点:“国家队”代表,语音强项。 依托科大讯飞在智能语音领域二十多年的深厚积累,是多模态能力的坚定推动者。
百度 - 文心一言(ERNIE Bot)
- 核心特点:老牌巨头,生态整合。 依托百度强大的搜索数据、知识图谱和全栈AI技术积累,是国内最早发布、应用最广泛的模型之一。中文理解深刻,与百度搜索、文库、地图等产品生态深度融合
月之暗面 - Kimi
- 核心特点:“长文本之王”,极致体验。 专注于提升模型的上下文处理能力,是其最核心的杀手锏。在长文档总结、信息检索、跨文档知识问答等领域一骑绝尘,用户体验口碑极佳。
小结#
黑马智聊机器人搭建核心有哪几步?
- 完成Ollama平台部署
- 调用Qwen2等大模型,完成基座模型构建
- 采用Streamlit构建聊天机器人前端页面
常见的大模型分类?
- 自然语言处理大模型
- 语言大模型
- 计算机视觉大模型
- 多模态大模型
列举几个国内主流大模型?
- 深度求索 - DeepSeek
- 阿里巴巴 - 通义千问(Qwen)
- 智谱AI - ChatGLM